Después de un fin de semana de descanso de exámenes y aprovechando la temática del proyecto de fin de carrera pensé en aplicar la misma técnica que empleo para topic detection a detección de malware.
El proceso muy por encima consiste en extraer la "semántica" (mediante word2vec) de las instrucciones de un conjunto de programas de entrenamiento P (y por tanto de un programa completo, si modelamos por ejemplo la semántica de un programa como una combinación lineal de las semánticas de las instrucciones que lo componen) para construir una representación en un espacio continuo n-dimensional junto con otras características como por ejemplo las DLLS y las funciones de las que hace uso, una medida de empaquetamiento (ponderando la entropía y la aparición de secciones que dejan ciertos packers) entre otras que se pueden tener en cuenta (de momento solo son esas).
Una vez se tienen las representaciones vectoriales de las muestras de entrenamiento (prototipos) se emplea clasificación por vecinos más cercanos (NearestCentroid) para determinar si un determinado programa es malware o no (semántica del programa más cercana a las muestras malware o a las muestras no malware).
El código lo podéis clonar de su propio repo:
[Enlace externo eliminado para invitados]
Instalad primero las dependencias mediante el setup.py . Cuando estén instaladas tendréis que entrenar el sistema con vuestras propias muestras (no paso los ficheros de entrenamiento porque ocupan bastante si lo entrenas con muchas muestras) tenéis que meter muestras malware en ./Train/Malware y muestras no malware en ./Train/NoMalware y después indicarle al sistema que queréis entrenar, en el usage se muestra la forma de hacerlo, pero básicamente tenéis que lanzar lo siguiente:
Código: Seleccionar todo
python WinMalwareDetector.py --train ./Train/Malware ./Train/NoMalware prototypes.trained model_w2v.mm ffunctions.mmCódigo: Seleccionar todo
python WinMalwareDetector.py --predict EJECUTABLE.exe 1 prototypes.trained modelw2v.mm ffmodel.mmEsto es lo necesario para poner en marcha la clasificación, podéis comprobar la precisión y otras medidas del sistema sin tener que hacer el entrenamiento, solo poned las muestras malware y no malware donde dije y lanzad lo siguiente:
Código: Seleccionar todo
python WinMalwareDetector.py --statistics -lou 1 ./Train/Malware ./Train/NoMalwarePara que veáis las salidas del programa en los casos que os he comentado adjunto un par de imágenes:
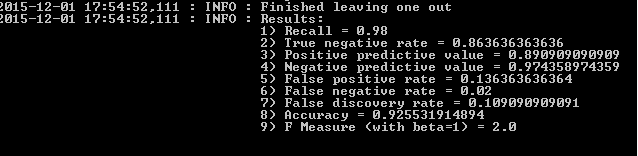
Estadísticas:
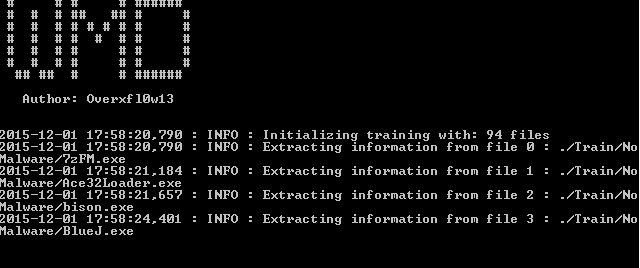
Clasificación:
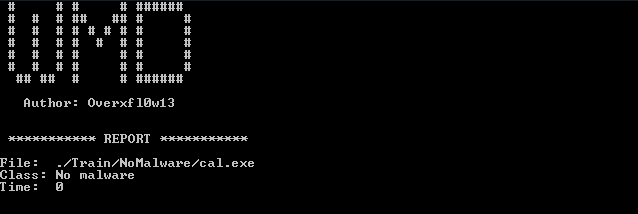
Predicción:
Saludos: Papaito over

